

Poprzedni wpis poświęcony był wskaźnikom efektywności procesów takim jak FTY, FPY czy RTY. Po skrócie objaśniliśmy sposób ich liczenia oraz kluczowe różnice. Aby móc liczyć wspomniane wskaźniki, potrzebne jest zebranie danych. Nie może to jednak odbywać się w sposób przypadkowy. Zanim jednak do zagadnienia związanego z arkuszami danych, skupmy się w pierwszej kolejności na systematyce danych w celu ich rozróżnienia oraz temu, które z nich wykorzystamy do liczenia wskaźników efektywności, a które będą wykorzystywane przy innych okazjach.
Podział cech stanowi wstęp do zagadnienia jakim jest analiza danych. Przejdziemy zatem przez kwestie związane z gromadzeniem danych za pomocą arkuszy danych nazywanych również arkuszami kontrolnymi, poprzez podstawowe narzędzia analizy danych aż po karty kontrolne Shewharta. Ale o tym dowiesz się przy okazji przyszłych wpisów.
Systematyka danych
Zanim przejdę do szczegółowego omówienia poszczególnych danych, zapoznajmy się w pierwszej kolejności z ich systematyką. Dlaczego jest to tak ważne? Przede wszystkim by odpowiednio sklasyfikować gromadzone dane, móc je w łatwy sposób posegregować, przygotować do analizy a następnie wykorzystać do liczenia wskaźników efektywności procesu, monitorowania przebiegu procesów czy podstawowej analizy wyników płynących z procesów.
Poniższa grafika przedstawia podstawową systematykę danych, z którymi spotkasz się w swojej pracy.
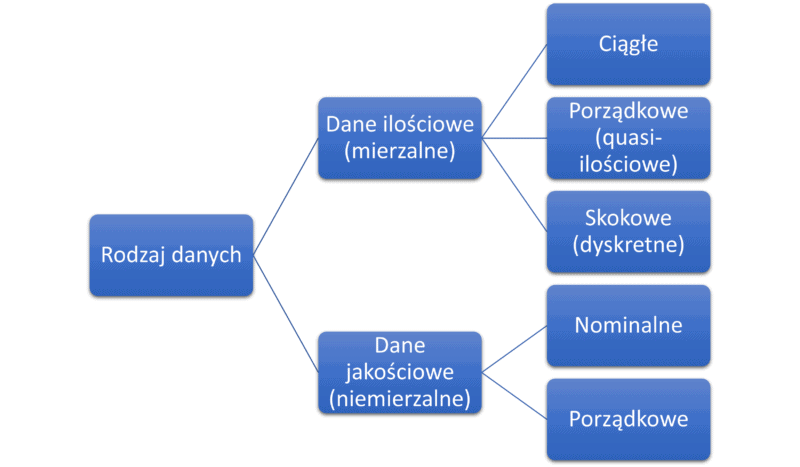
Wiesz już jak przedstawia się podstawowy podział danych. Teraz czas na to by dowiedzieć się czym różnią się od siebie te dane i w jaki sposób mogą zostać wykorzystane.
Dane ilościowe
Dane ilościowe inaczej nazywane danymi mierzalnymi, jak sama nazwa wskazuje, to dane, które można w przedstawić za pomocą wartości mierzalnych. Innymi słowy cechy ilościowe (mierzalne) dotyczą zmiennych, które wyrażone są najczęściej w postaci pewnej skali liczbowej.
Jak zatem będzie kształtował podział danych ilościowych na podgrupy? Jakie są ich podstawowe cechy danych ilościowych? Zacznijmy więc od danych ciągłych.
Dane ciągłe będą to dane składające się z cech wrażonych wartościami liczbowymi w określonym przedziale. W przypadku procesów wytwórczych, będziemy brali pod uwagę dane, które będą specyfikowane dla danego wyrobu lub procesu jak np.:
- moment obrotowy podawany w Nm
- długość przedstawiana np. w mm
- wielkość cząstek podawana w μm
- częstotliwość wyrażona w Hz
Przykłady można mnożyć, ale myślę, że ogólny zarys został przedstawiony jest zrozumiały.
Dane porządkowe inaczej nazywane również danymi quasi-ilościowymi. Są to dane, które są sklasyfikowane w grupach, ale nadal są danymi, które możemy śmiało przedstawić za pomocą wartości. I tak przykładem danych porządkowych będzie dla przykładu;
- długość (krótki, średni, długi)
- waga (lekki, ciężki)
- prędkość (powoli, szybko)
Jak możesz zauważyć są to dane, które, mimo iż są mierzalne, przedstawione zostały jako grupy, które nie odnoszą się bezpośrednio do wartości liczbowych.
Kolejną podgrupą, danych ilościowych, będą dane skokowe, nazywane również danymi dyskretnymi. Są to również dane, które można przedstawić za pomocą wartości liczbowych. To co będzie odróżniać dane skokowe od danych ciągłych będzie to, że dane te przyjmują najczęściej wartości liczb naturalnych. Będą więc to dane, do których będziemy zaliczać np.:
- czas składowania (podany w miesiącach)
- czas trwania procesu (minuty, godziny)
- ilość części wadliwych (sztuki)
- czas dostawy (mierzony np. w dniach)
Wiesz już więc jakie dane będziemy uznawać za mierzalne. Czas więc przejść do drugiej grupy.
Dane jakościowe
Dane jakościowe są kolejną grupą danych przyjętą w klasyfikacji danych. W odróżnieniu jednak od danych ilościowych są to cechy nie są mierzalne w żaden sposób. Żeby dane takie mogły być w jakikolwiek sposób analizowane, wymagana jest ich „wstępna obróbka”. Oznacza to więc, że będą one wymagały kwantyfikacji. Ale o tym przy okazji innego wpisu.
O jakich danych więc będziemy w tym przypadku mówili?
Dane nominalne, a więc dane, dla których będziemy przypisywali wartość liczbową, ale każda z nich będzie miała taką samą ważność. Przykładem cechy nominalnej będzie więc;
- wada występuje – tak / nie
- maszyna – włączona / wyłączona
Dane porządkowe w przypadku danych jakościowych będą więc odzwierciedlać informacje dotyczące cech, dla których będziesz podawał natężenie, a więc częstotliwość z jaką występuje dana cecha. Najlepszym przykładem będzie tutaj klasyfikacja wad w procesie.
Kwantyfikacja danych jakościowych porządkowych posłuży zarówno do liczenia wskaźników, o których była mowa w poprzednim wpisie. Cechy te będzie też można w łatwy sposób analizować przy użyciu chociażby analizy Pareto-Lorenza, który przybliżę przy okazji przyszłych wpisów.
Choć systematyka danych może wydawać się dość skomplikowana na pierwszy rzut oka, to po bliższym zapoznaniu się ze szczegółami, będziesz w stanie w łatwy sposób ocenić jak przygotować arkusz danych w sposób odpowiedni dla danej cechy jak również analizować dane wychodzące z procesu.
Systematyka danych wg. Stevensa
Stanley Smith Stevens przestawił inne podejście do systematyki danych podczas prowadzonych przez siebie badań nad cechami statystycznymi.
Poniższą klasyfikację przedstawiam jako ciekawostkę. Nie odbiega ona znacząco od tego co zostało omówione we wcześniejszych paragrafach. Nie zaprzeczam jednak, że niektórzy z czytelników mogą być bardziej zaznajomieni akurat z systematyką, którą przedstawił Stevens w swoich badaniach.
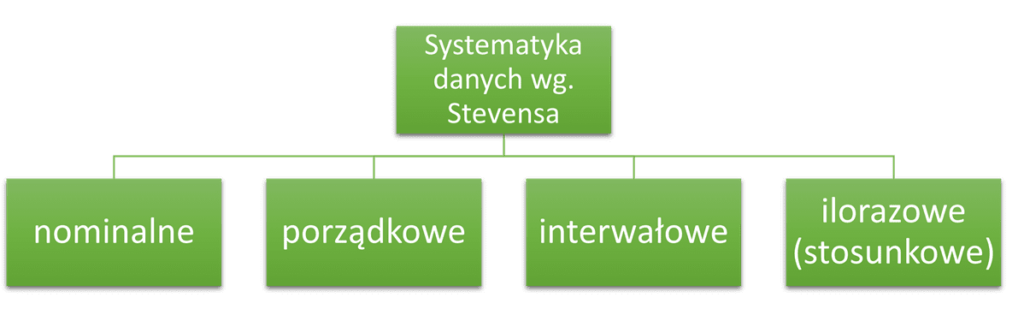
Zmienne nominalne to dane, które pozwalają tylko na pogrupowanie obiektów. Będą one więc odpowiadać danym quasi-ilościowym.
Zmienne porządkowe pozwalają tylko na uporządkowanie obiektów wg wartości, jakie przyjmują zmienne dla tych obiektów. W tym przypadku dane te będą odpowiadać danym jakościowym porządkowym
Zmienne interwałowe pozwalają na stwierdzenie, o ile natężenie zmiennej dla jednego obiektu jest większe (mniejsze) od natężenia zmiennej dla drugiego obiektu. Przykładem przedstawienia takich danych będzie wskazanie o ile wielkość cząstek dla próbki z pierwszego pobrania będzie większa od wielkości cząstek z pobrania drugiego.
Dla przykładu przyjmijmy, że dokonujemy pomiaru grubości warstwy lakieru na malowanym elemencie. Pomiar prowadzony przy użyciu miernika grubości wskazuje mierzoną wartość dla próbki A na poziomie 70 μm. W przypadku drugiej próbki, pomiar grubości lakieru dokonany w tym samym miejscu, na drugiej próbce, za pomocą dokładnie tych samych metod pomiarowych wyniósł 80 μm. Różnica w pomiarze wynosi więc 10 μm. W tym przypadku stwierdzimy więc, interpretując wyniki pomiaru, że wartość próbki A jest o 10 μm mniejsza od wartości zmierzonej na próbce B. Lub odwrotnie, wartość próbki B będzie większa o 10 μm od wartości zmierzonej na próbce A.
Zmienne ilorazowe (stosunkowe) pozwalają dodatkowo na stwierdzenie, że natężenie wybranej cechy dla próbki A jest n razy większe niż natężenie tej samej cechy dla próbki B. Dobrym przykładem będą tutaj choćby odległość pomiędzy miastami czy czas reakcji zawodników na sygnał startu.
Podsumowanie
Reasumując, informacje przedstawione w tym wpisie, będą dla Ciebie pomocne, zarówno przy określaniu jakiego rodzaju dane dostarczają procesy, z którymi pracujesz. Dzięki temu łatwiej będzie Ci dobrać odpowiednią metodę ich gromadzenia. Przygotować właściwy arkusz danych lub kartę kontrolną, a na koniec obrać właściwy sposób ich analizy.
W przyszłych wpisach pokażę Ci jakich narzędzi używać do gromadzenia danych z procesu oraz jakie narzędzia będą właściwe do ich analizy.



