Temat dotyczący systematyki danych, stanowił poniekąd wstęp do bardziej szczegółowego omówienia danych gromadzonych z procesu. Przedstawiłem również jak przygotować arkusze do gromadzenia danych. Pokazałem w jaki sposób możemy gromadzić zarówno dane ilościowe jak również dane jakościowe.
W dzisiejszym wpisie będę chciał przypomnieć czym są dane ilościowe jakich narzędzi używać do ich analizowania oraz jak czytać wyniki za pomocą poszczególnych narzędzi do analizy danych. Narzędzia, o których dzisiaj będzie mowa, zostały również przez mnie przy toczone przy okazji innych wpisów,
Dane ilościowe – przypomnienie
Słowem krótkiego wstępu przypomnijmy sobie czym są dane ilościowe i jak są klasyfikowane.
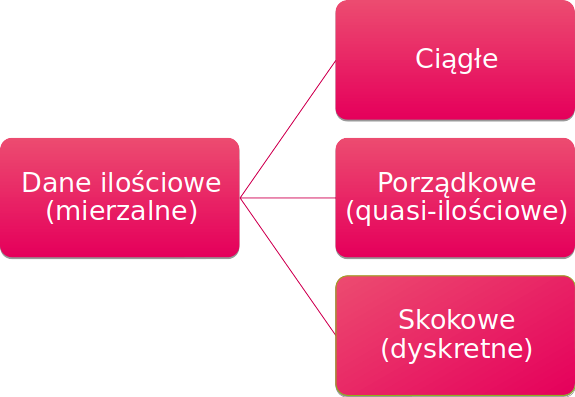
Dane ilościowe inaczej nazywane danymi mierzalnymi, jak sama nazwa wskazuje, to dane, które można w przedstawić za pomocą wartości mierzalnych. Innymi słowy cechy ilościowe (mierzalne) dotyczą zmiennych, które wyrażone są najczęściej w postaci pewnej skali liczbowej.
Dane te dzielimy na następujące podgrupy;
Dane ciągłe będą to dane składające się z cech wrażonych wartościami liczbowymi w określonym przedziale. W przypadku procesów wytwórczych, będziemy brali pod uwagę dane, które będą specyfikowane dla danego wyrobu lub procesu jak np.:
- moment obrotowy podawany w Nm
- długość przedstawiana np. w mm
- wielkość cząstek podawana w μm
- częstotliwość wyrażona w Hz
Przykłady można mnożyć, ale myślę, że ogólny zarys został przedstawiony jest zrozumiały.
Dane porządkowe inaczej nazywane również danymi quasi-ilościowymi. Są to dane, które są sklasyfikowane w grupach, ale nadal są danymi, które możemy śmiało przedstawić za pomocą wartości. I tak przykładem danych porządkowych będzie dla przykładu;
- długość (krótki, średni, długi)
- waga (lekki, ciężki)
- prędkość (powoli, szybko)
Jak możesz zauważyć są to dane, które, mimo iż są mierzalne, przedstawione zostały jako grupy, które nie odnoszą się bezpośrednio do wartości liczbowych.
Kolejną podgrupą, danych ilościowych, będą dane skokowe, nazywane również danymi dyskretnymi. Są to również dane, które można przedstawić za pomocą wartości liczbowych. To co będzie odróżniać dane skokowe od danych ciągłych będzie to, że dane te przyjmują najczęściej wartości liczb naturalnych. Będą więc to dane, do których będziemy zaliczać np.:
- czas składowania (podany w miesiącach)
- czas trwania procesu (minuty, godziny)
- ilość części wadliwych (sztuki)
- czas dostawy (mierzony np. w dniach)
Sposoby graficznej analizy danych ilościowych
Diagram przebiegu w czasie
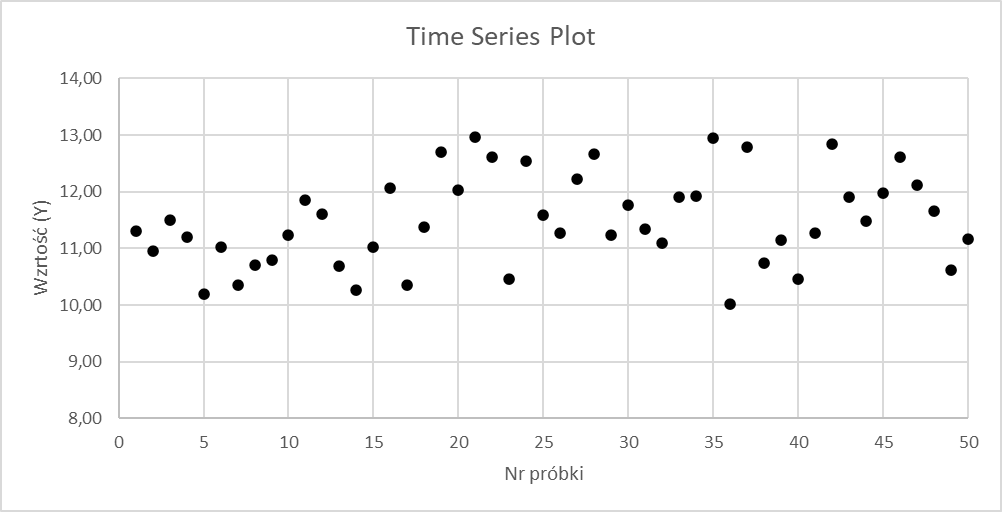
Diagram przebiegu w czasie (ang. Time Series Plot), to jeden z najprostszych do zastosowania wykresów podczas prezentacji danych ilościowych, który jest w stanie dostarczyć nam informacje na temat kształtowania się badanej cechy w czasie. Dzięki nanoszeniu wyników na kartę w postaci punktów, jesteśmy w stanie zaprezentować jak badana przez nas cecha rozkładała się, czy to w zależności od pobranych do badań próbek czy też w zależności od czaso-okresu, w którym poddawaliśmy interesującą nas cechę badaniom.
Ten sposób prezentowania danych ilościowych, bedzie stanowił dla nas punkt wyjścia do zbudowania kart kontrolnych. Ale o tym za chwilę.
Histogram
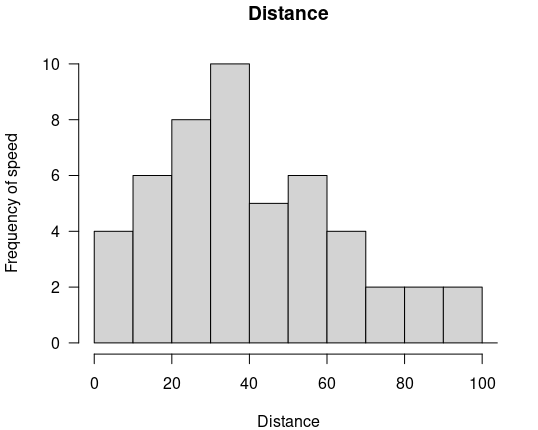
Histogram to nic innego jak graficzne przedstawienie rozkładu częstotliwości występowania wartości danej cechy. Innymi słowy mówiąc, wykres obrazuje dane ilościowe za pomocą słupków, które odpowiadają częstotliwości występowania danej wartości zawartej w określonych przedziałach. Oczywiście przedziały te mogą być zmienne i zależne od wprowadzanego zakresu.
Przykład przedstawiony powyżej, prezentuje częstotliwość występowania danej odległości dla wybranej grupy pojazdów. Każdy ze słupków pokazuje ile pojazdów było w stanie przejechać określony dystans w przedziałach co 10km. Im wyższy słupek, tym więcej pojazdów było w stanie osiągnąć daną odległość.
W ten sam sposób, będziemy zatem analizować rozkład wartości dla parametrów procesów poddawanych analizie. I tak dla przykładu, możemy badać wspominany tak często przytaczany przeze mnie moment obrotowy (Nm), temperaturę (C), prędkość posuwu (Hz) itd. Czyli wszystkie dane ilościowe, które można przedstawić w sposób skwantyfikowany.
Celowo nie zajmuję się dzisiaj badaniem rozkładu pod kątem normalności, ponieważ ten temat przybliżę podczas rozważań na temat statystycznej kontroli procesu (SPC).
Karty kontrolne (Karty Shewharta)
Karty kontrolne to jedno z podstawowych narzędzi stosowanych w celu badania odchyleń pojawiających się w procesach. Ten typ kart kontrolnych nazywa się też często kartami Shewharta, który uważany jest za prekursora tego sposobu metod pomiarów i analizy procesów.
Na czym więc polegać będzie analiza danych ilościowych za pomocą kart kontrolnych? Do tego aby skutecznie móc monitorować proces za pomocą kart Shewharta musimy wykonać następujące czynności;
- pobrać odpowiednią ilość prób z danego momentu w procesie
- dokonać pomiaru cechy
- określić, na podstawie zmiennej wartości próbek granice kontrolne
- monitorować trendy i niepokojące sytuacje (np. przekroczenie granic kontrolnych lub dużą rozbieżność pomiędzy kolejnymi próbkami) zachodzące w procesie
- dokonać oceny czy proces uległ rozregulowaniu
- przeprowadzić analizę przyczyn rozregulowania procesu.

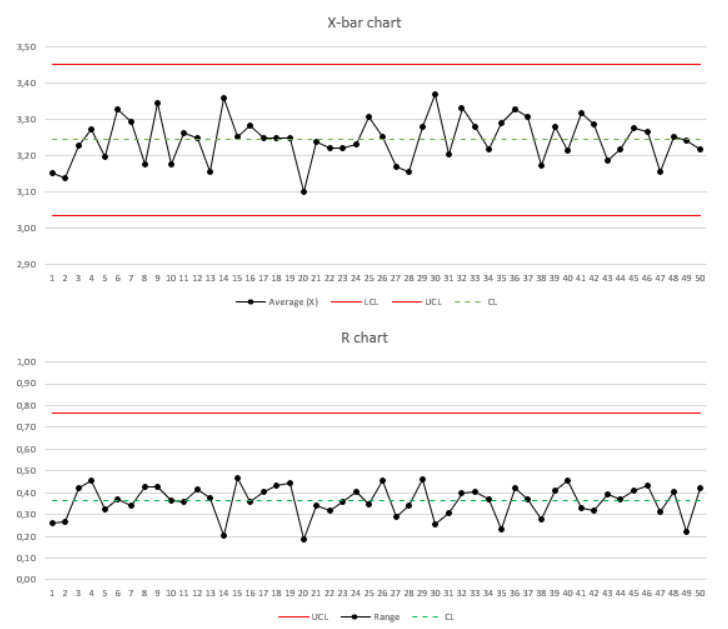
Ponieważ, dzisiejszy wpis poświęcony jest danym ilościowym, poniżej prezentuję tylko skrócony opis wybranych kart. Osobny wpis poświęcony będzie szczegółowemu omówieniu zagadnienia kart kontrolnych jak również całemu procesowi statystycznego sterowania procesem (SPC). Niecierpliwych i głodnych wiedzy odsyłam w międzyczasie do leksykonu StatSoft gdzie oprócz kart kontrolnych przedstawione są inne istotne z punktu widzenia statystyki narzędzia.
Karty średniej i rozstępu (x-R) – karty statystyczne służące do przedstawienie na karcie uśrednionych wartości z kontrolowanych w czasie prób jak również rozstępu pomiędzy nimi. Przykładem może być wartość momentu obrotowego dla połączeń gwintowanych.
Karty wartości indywidualnych i ruchomego rozstępu (I-MR) – stosowana dla porównania zmierzonych cech dla każdej próbki indywidualnie pobranej z całego zbioru prób. Zakładamy więc, że mamy 30 szt. pobranych do pomiaru średnicy wałka. Każdy wałek mierzymy w tym samym miejscu a otrzymane wartości nanosimy na kartę sprawdzając jak kształtują się kolejne pomiary. W tym przypadku dodatkowo sprawdzamy rozstęp pomiędzy kolejnymi pomiarami następującymi po sobie. Rozstęp ten będziemy określać jako ruchomy.
Karty kontrolne średniej i odchylenia standardowego (x-S) – tak jak ma to miejsce w przypadku kart x-R również na kartę nanoszone są wartości średnie dla danej próby ale zamiast rozstępu badane jest odchylenie standardowe pomiędzy wynikami dla danej próby.
Karty kontrolne wartości środkowej i rozstępu (MD-R) – na koniec, rzadziej używana ale nie oznacza to, że mniej przydatna, karta wartości środkowej (MD) i rozstępu (R). W tym przypadku kluczowe będzie naniesienie na kartę jednej szczególnej wartości (wartości środkowej) reprezentującej daną próbę. Rozstęp natomiast, będzie liczony i przedstawiany jak w przypadku kart x-R.
Wykres pudełkowy
Wykresy pudełkowy został zaproponowany i rozpowszechniony przez Johna Turkeya w latach 90-tych ubiegłego wieku. Ten szczególny wykres opracowany został w oparciu o wartości statystyk opisowych, dlatego też jest przeznaczony jedynie do przedstawiania danych ilościowych lub inaczej mówiąc cech, które zostały skwantyfikowane tj. przedstawione liczbowo.
Głównym celem przedstawienia danych za pomocą wykresu pudełkowego jest zobrazowanie w prostej formie graficznej rozkładu cechy statystycznej. Jest to możliwe dzięki ujęciu na jednym rysunku wszystkich wiadomości, które dotyczą położenia, kształtu, a także rozkładu empirycznego badanej cechy.
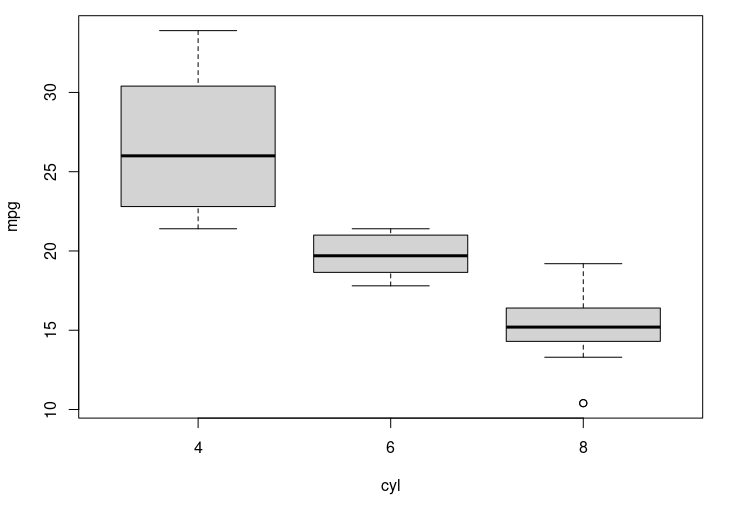
Przykład zilustrowany powyżej, przedstawia różnice pomiędzy dystansem jaki może pokonać pojazd na jednym galonie paliwa w zależności od ilości cylindrów. Przedstawione dane zwracają nam więc informację na temat następujących cech;
- mediany czyli wartości środkowej rozkładu badanej cechy (uwaga! nie jest to wartość średnia),
- wartości maksymalnych i minimalnych (końce wąsów) dla badanych cech,
- zdarzeń specjalnych (ang. outliers), tj. punktów poza wartościami min lub max będące wynikiem błędu przeprowadzonego testu, zdarzenia losowego lub szczególnej specyfiki badanego przedmiotu,
- rozstęp ćwiartkowy lub inaczej nazywany też międzykwartylowym (szary prostokąt), który dostarcza nam informacji w jakim zakresie znajduje się 50% badanej populacji.
W skrócie. Jeżeli zaczniemy analizować pojazdy czterocylindrowe pod kątem przejechanych mil na jednym galonie paliwa to zauważymy, że badana grupa pojazdów cechowała się następującymi danymi;
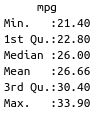
Szczegółowy opis na temat tego jak czytać dane za pomocą Box Plot, jakie jest ich powiązanie z analizą graficzną w formie histogramu i kart statystycznych zostanie przedstawione przy okazji omawiania tematów związanych ze statystyczną kontrolą procesów.
Wykres rozrzutu
Wykres rozrzutu (ang. scatterplot), potocznie nazywany również wykresem punktowym, to graficzne narzędzie przedstawiające relacje pomiędzy dwiema ilościowymi zmiennymi mierzonymi dla tych samych cech. Wartości jednej zmiennej prezentowana jest na osi poziomej, a wartości pozostałych zmiennych pojawiają się na osi pionowej. W wyniku naniesienia danych na wykresie, pojawiają się punkty wyznaczające rezultat zależności jednej zmiennej od drugiej.
Kiedy więc będziemy stosowali wykres rozrzutu? Kiedy np. będziemy badali jaki jest wpływ pojemności silnika spalinowego na wielkość zużycia paliwa w wybranej grupie pojazdów. Przekładając to na język produkcji, możemy np. w ten sposób prezentować wpływ temperatury i czasu podczas suszenia powłoki lakierniczej.
Ogólnym założeniem wykresu rozrzutu jest wskazanie, kierunku, kształtu oraz stopnia w jakim obie zmienne są ze sobą powiązane. Ostatecznie możemy spotkać się z następującymi relacjami, takimi jak zaprezentowane na poniższej grafice.
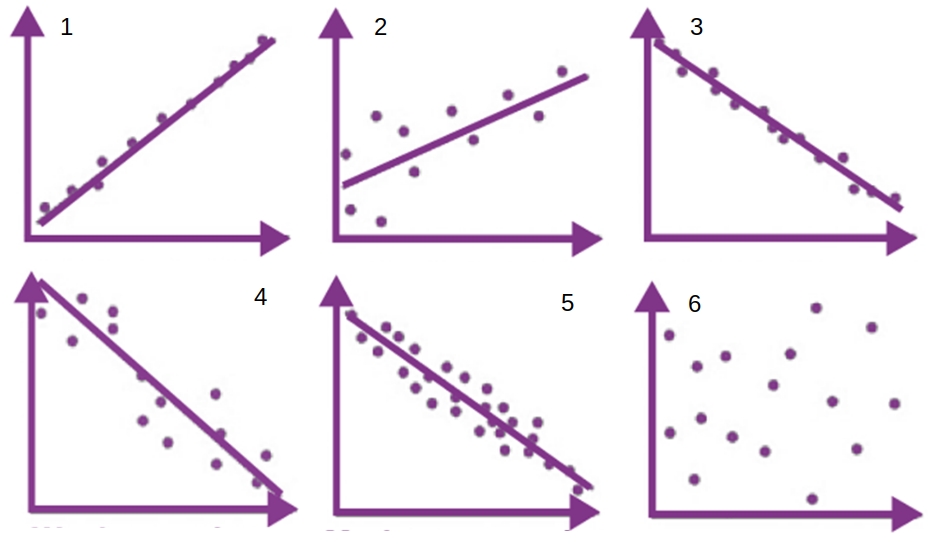
Jak czytać powyższe wykresy?
- silna korelacja dodatnia – będzie mówiła nam o tym, że wzrost wartości jednej cechy, będzie w takim samym stopniu powodował wzrost drugiej cechy
- słaba korelacja dodatnia – świadczy o tym, że wzrost dodatni jednej cechy będzie powodował nieznaczne zmiany dodatnie w przypadku drugiej cechy
- silna korelacja ujemna – wzrost jednej cechy powoduje w równym stopniu spadek drugiej cechy
- słaba korelacja ujemna – będzie odpowiadała za nieznaczny spadek jednej z cech przy równoczesnym wzroście drugiej badanej cechy
- umiarkowana korelacja dodatnia/ujemna – niewielka zależność pomiędzy cechami
- brak zależności – czyli nic innego jak całkowity brak powiązania pomiędzy badanymi cechami.
Wykres punktowy, wykorzystywany jest w szczególności przy opisywaniu zjawisk podczas badania korelacji Pearsona (korelacja liniowa dodatnia lub regresja liniowa) lub też stosowany jest do zobrazowania danych ilościowych podczas wyliczania współczynnika korelacji rang Spearmana. W tym jednak szczególnym przypadku liczebność badanych jest niewielka
Zarówno o korelacji Pearsona jak i Spearmana porozmawiamy więcej przy innej okazji.
Podsumowanie
Dzisiejszy wpis to tylko wstęp do głębszych rozważań nad statystyką, badaniem rozkładów oraz zdolności procesów w oparciu o dane ilościowe. W przyszłych wpisach przybliżę więc nie tylko jak odpowiednio czytać i analizować dane ale również jak metody przeprowadzania testów na danych ilościowych są ze sobą powiązane i jakich informacji są nam w stanie jeszcze dostarczyć.
Ostatecznym celem jest bowiem podzielić się wiedzą na temat statystycznej analizy procesu jak również zrozumienia zmienności pojawiającej się w procesach oraz jak radzić sobię z sytuacjami szczególnymi.